
Post pubblicato il 10 settembre 2008 in blogs.technet.com/terminologia. Nel frattempo la traduzione automatica ha avuto sviluppi e miglioramenti molto importanti e il nome del servizio di traduzione automatica di Microsoft è diventato Bing Translator.
Fino a qualche giorno fa il servizio di traduzione automatica di Windows Live Translator offriva due opzioni: la tecnologia Microsoft Research per testo con contenuto informatico e un sistema di terze parti, sviluppato da Systran, per testo generico, come si può vedere in questa vecchia schermata:
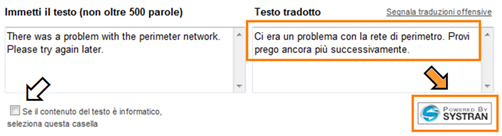
Lunedì il team MSR-MT ha annunciato che ora tutte le coppie di lingue disponibili in Windows Live Translator, tra cui italiano-inglese e inglese-italiano, utilizzano solamente tecnologia Microsoft:
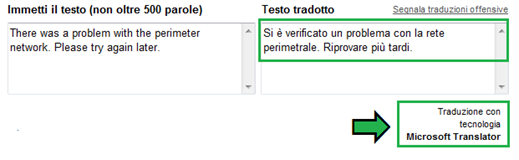
Ho fatto un po’ di prove e i risultati sono decisamente migliorati.
L’annuncio è interessante anche perché il sistema di traduzione automatica sviluppato da Microsoft (MSR-MT) è un sistema ibrido con un motore di tipo statistico mentre il modello Systran, che continua ad essere usato ad es. da Babel Fish, era principalmente basato su regole. Anche Google l’anno scorso è passata definitivamente da Systran a un proprio sistema di tipo statistico per tutte le coppie di lingue.
Semplificando al massimo, i sistemi basati su regole analizzano il testo di partenza per poi generare il testo di arrivo applicando regole di trasformazione. Per ogni lingua nel sistema è necessario definire regole precise di tipo morfologico, sintattico e semantico e un lessico di riferimento.
I sistemi di tipo statistico come quello Microsoft, invece, vengono "addestrati" (il training) con milioni di frasi da testi paralleli, ovvero testo originale e relativa traduzione umana. Non è necessario definire regole individuali per ciascuna lingua perché il sistema "impara" a riconoscere le corrispondenze tra parole e segmenti di frase in ogni coppia di lingue e assegna una probabilità più alta alle associazioni più ricorrenti, in modo da poterle poi riprodurre in fase di traduzione applicando altri algoritmi e parametri statistici.
Inizialmente il motore di traduzione MSR-MT era focalizzato su contenuto di tipo informatico perché era destinato alla traduzione automatica di articoli del sito Aiuto & Supporto (Knowledge Base). Il training era effettuato in particolare con le memorie di traduzione dei prodotti Microsoft.
Per il training di un sistema di tipo statistico sono necessari notevole potenza di elaborazione e corpora bilingui enormi. Ovviamente qualità, varietà e quantità dei corpora usati per il training sono tra i tanti fattori che incidono sul risultato finale: se il sistema non è stato esposto a particolari tipi di testo, potrebbe avere più difficoltà a tradurli in maniera soddisfacente.
Negli ultimi anni sono aumentate le iniziative per la condivisione di memorie di traduzione, ad es. da parte della Commissione europea. L’accesso a corpora paralleli vastissimi e diversificati e a computer sempre più potenti non può che dare un ulteriore impulso al perfezionamento dei sistemi di traduzione automatica ibridi con un motore di tipo statistico.
I margini di miglioramento sono comunque veramente ampi, come sanno tutti quelli che hanno avuto a che fare con testo tradotto automaticamente. Chi lavora in questo campo non è certo a rischio di disoccupazione!
Vedi anche: Altre informazioni sulla traduzione automatica.
Aggiornamento: un video di Google, con sottotitoli in italiano, che spiega come funziona il proprio sistema di traduzione automatica e sintetizza le differenze tra sistemi basati su regole e di tipo statistico:
1 commento su “Traduzione automatica: Windows Live Translator”
I commenti sono chiusi.